Зачем нужен валидный код и как устранить ошибки валидации. Структура Урл адреса и перекодировка в URL-encoded
к.э.н. Лавлинский Н. Е., технический директор ООО «Метод Лаб»
Недавно опубликован новый стандарт на технологию Preload (ссылка). Основной задачей этой спецификации было обеспечить возможность тонкого управления логикой загрузки ресурсов страницы разработчиком.
Предыдущие стандарты
Идея об управлении загрузкой не нова. Ранее были разработаны несколько вариантов тегов link с атрибутами subresource , prerender и prefetch . Однако, они работали несколько иначе: с их помощью можно загружать элементы страниц или целые страницы, которые могут потребоваться при дальнейшей навигации по сайту. То есть, браузер отправлял такие запросы с низким приоритетом и в последнюю очередь. Если же нужно повысить приоритет, то решений не было.
Загрузка ресурсов с preload
Что же даёт новая спецификация? Во-первых, теперь загрузка происходит с уточнением, что загружается. Исходя из указанного типа ресурса браузером выставляется приоритет загрузки. Например:
link rel = "preload" href = "/js/script.js" as= "script" >link rel = "preload" href = "/fonts/1.woff2" as= "font" type = "font/woff2" crossorigin>
Во-вторых, тип ресурса (as ) позволяет браузеру послать правильные заголовки, чтобы сервер мог отправить контент с лучшим вариантом сжатия (например, послать WebP картинки, если браузер их поддерживает).
Во втором примере мы загружаем файл шрифта, при этом указан конкретный формат (WOFF2), который поддерживается не всеми браузерами. Однако, пока поддержка механизма preload совпадает с поддержкой такого формата, проблем не возникает. Текущую поддержку механизма можно посмотреть .
Ускоренная загрузка шрифтов
В качестве примера ускорения сайта с использованием preload можно назвать загрузку глубоко закопанных ресурсов, например, шрифтов. В обычном процессе загрузки браузер должен сначала загрузить CSS-файл с указанием на шрифт, провести парсинг этого файла и только потом поставить в очередь запрос на скачивание файла шрифта.
Если мы укажем preload этого шрифта в коде HTML-страницы, браузер отправит запрос сразу же после разбора HTML-документа, что может быть на несколько секунд раньше, чем в обычном случае. А мы знаем, что подключаемые шрифты являются блокирующими элементами и задерживают отрисовку шрифта на странице, поэтому загрузить их нужно как можно быстрее. Особенно остро эта проблема стоит при использовании HTTP/2, когда браузер отправляет сразу множество запросов к серверу, в результате чего какие-нибудь картинки могут заполнить полосу клиента и загрузка важных ресурсов будет отложена.
Асинхронная загрузка CSS
CSS-файлы всегда блокируют рендеринг страницы, поэтому все CSS-ресурсы, загрузку которых можно отложить, можно загружать как обычные файлы и динамически подключать к странице.
Делается это следующим образом:
link rel = "preload" as= "style" href = "async_style.css" onload = "this.rel="stylesheet"" >Загрузка JS-кода без исполнения
Также полезным может оказаться предзагрузка кода скрипта на JS, чтобы выполнить его позже.
Это можно сделать с помощью следующего кода:
link rel = "preload" as= "script" href = "async_script.js" onload = "var script = document.createElement("script"); script.src = this.href; document.body.appendChild(script);" >Мы рассмотрели основные способы использования механизма preload, но возможности на этом не ограничиваются, проводите собственные эксперименты!
В последнее время неоднократно всплывает тема загрузки ресурсов. Вкратце: «Я загружаю картинку из c:\work\image.gif, а когда запускаю программу из jar-файла/на другом компьютере – она не грузится. Что делать?».
Между тем, ничего сложного тут нет. Надо только понимать принципы.
Прежде всего, грузить ресурсы по абсолютному адресу на диске – занятие бесперспективное. Думаю, сами прекрасно понимаете, почему – убрали файл с диска, и «прощай ресурс». Всё свое надо носить с собой.
Второй вариант, который я часто вижу, – загрузка ресурса из jar-файла. Но тут очень часто делается одна ошибка – ресурс пытаются грузить через класс java.io.File . При том, что этот класс предназначен только для работы с файловыми системами.
Хотя сама идея правильная. Нужный ресурс действительно необходимо поместить в jar-файл. Надо только понимать, как его оттуда загрузить. Вот об этом я и расскажу.
Для загрузки ресурса служат методы java.lang.Class.getResource(String) , java.lang.Class.getResourceAsStream(Stri ng) , java.lang.ClassLoader.getResource(String) и java.lang.ClassLoader.getResourceAsStrea m(String) . Методы Class -а делегируют вызовы ClassLoader -у.
GetResource(String) по имени ресурса возвращает java.net.URL , через который можно получить этот ресурс. getResourceAsStream(String) , как нетрудно догадаться, возвращает java.io.InputStream , через который ресурс можно прочитать.
Имя ресурса представляет собой путь к ресурсу. Есть одна существенная тонкость, а именно – как оно интерпретируется.
Имя может быть абсолютным и относительным. Внешнее отличие – абсолютное имя начинается с символа "/". В первом случае ресурс ищется относительно корня classpath. Т.е. берутся все пути и jar-файлы, входящие в classpath, и ресурс ищется относительно совокупности этих точек. Если же имя относительное – к нему в начало приписывается путь, полученный из пакета текущего класса. Далее поиск ведется как в случае абсолютного имени.
Проще это понять на примерах. Пусть у нас задан classpath: c:\work\myproject\classes;c:\lib\lib.jar . Код примера находится в классе ru.skipy.test.ResourceLoadingTest .
Пример 1 . Мы используем конструкцию getClass().getResource("/images/logo.svg") . Поскольку имя начинается с символа "/" – оно считается абсолютным. Поиск ресурса происходит следующим образом:
- К пути из classpath c:\work\myproject\classes приписывается имя ресурса /images/logo.svg , в результате чего ищется файл c:\work\myproject\classes\images\logo.pn g . Если файл найден – поиск прекращается. Иначе:
- В jar-файле c:\lib\lib.jar ищется файл /images/logo.svg , причем поиск ведется от корня jar-файла.
- К пути из classpath c:\work\myproject\classes приписывается текущий пакет класса, где находится код, – /ru/skipy/test , – и далее имя ресурса res/data.txt , в результате чего ищется файл c:\work\myproject\classes\ru\skipy\test\r es\data.txt . Если файл найден – поиск прекращается. Иначе:
- В jar-файле c:\lib\lib.jar ищется файл /ru/skipy/test/res/data.txt (имя пакета текущего класса плюс имя ресурса), причем поиск ведется от корня jar-файла.
Вот тут можно скачать полностью рабочий пример, иллюстрирующий оба типа загрузки: . Ресурсы – изображение и текст – располагаются в отдельной директории, при сборке попадают в jar-файл и грузятся один по абсолютному, другой по относительному имени. Пример собирается и запускается через ant , командой ant run он запускается из директории сборки build/classes/ , командой ant run-jar – из собранного jar-файла.
Вот, где-то так. Вопросы? Комментарии?
Валидация является одним из самых важных аспектов хорошего веб-дизайна. Давайте рассмотрим, что это такое и как проверить HTML код на валидность. В качестве примера возьмем самую распространенную систему управления контентом (CMS) – WordPress. После чего мы поделимся перечнем ошибок, с которыми столкнулись на практике и, самое главное, предложим свои, проверенные, методы по их устранению.
Зачем необходима проверка на валидность сайта
Проще говоря, проверка веб-страницы позволит определить, соответствует ли она стандартам, разработанным Консорциумом Всемирной паутины (W3C). Обычно это делается путем проверки отдельных страниц на валидность с помощью онлайн-сервиса проверки от W3C .
Подобно правилам грамматики на разных языках, есть также правила в программировании. Проверка позволяет увидеть, соответствует ли страница этим правилам, а в случае наличия ошибок и предупреждений будут предоставлены рекомендации по их устранению. Подробнее о необходимости такой проверки рассмотрим ниже.
На что влияет валидность сайта
Вы когда-нибудь задумывались о том, как браузеры “читают” веб-страницу? У них есть “двигатели” для анализа кода и преобразования его в визуальный вид для людей. К сожалению, у каждого браузера есть собственный механизм обработки кода, и это может привести к отображению ваших страниц по-разному.
Некорректная веб-страница может быть прочитана браузерами по-разному. Это приведет к тому, что ваши посетители, возможно, даже не смогут правильно увидеть контент страницы в своих браузерах. Валидация в дальнейшем позволит исправить почти все основные различия и делает вашу веб-страницу доступной для чтения почти всеми веб-браузерами (чаще всего исключением становится Internet Explorer старых версий). Отсюда и появился термин “кроссбраузерная верстка” – т.е. верстка, которая одинаково хороша (совместима) для всех популярных браузеров.
А как же это повлияет на SEO? Важно понимать, что роботы поисковых систем любят семантические веб-страницы. Семантическая верстка, согласно данным Википедии, – это подход к созданию веб-страниц на языке HTML, основанный на использовании HTML тегов в соответствии с их семантикой (предназначением). Кроме того, структурная семантическая веб-страница позволяет поисковым роботам более точно определять значимость, как отдельных элементов веб-страницы, так и всего текста в целом. По заверению Google, валидный код никак не влияет на ранжирование страниц. Но при этом наличие ошибок в коде способно негативно повлиять на сканирование микроразметки и адаптированностью под мобильные устройства.
Инструменты проверки для вашего сайта
Понимая необходимость отсутствия ошибок валидации на страницах сайта, давайте рассмотрим, как осуществить поиск данных ошибок.
Существует множество бесплатных сервисов для проверки сайта, такие как Markup Validation Service W3C , Web Page Analyzer , Browsershots и другие.
Я решил продолжить эту актуальную тему. Я составил список лучших ресурсов для изучения html и css, чтобы помочь желающим в изучении этих вопросов. Помню, когда сам начинал вебмастером, мне очень не хватало подобной подборки качественных и полезных ресурсов.
Сначала немного определений:
Html (от английского "HyperText Markup Language" - язык разметки гипертекста) - это стандартный язык разметки веб-страниц.
Css (от английского "Cascading Style Sheets" - каскадные таблицы стилей) - это технология описания внешнего вида веб-страницы.
Без знания html и css вести свой сайт будет очень проблематично - даже счетчик статистики или тот же баннер поставить не получится. Не бегать же за помощью к специалистам или создавать тему за темой на форумах? Нужно просто взять и выучить.
По своему опыту могу сказать, что html и css можно выучить за 1 месяц. Конечно, я не говорю о профессиональных высотах - вы до них сами доберетесь при желании.
На мой взгляд, лучший способ выучить html, css, да и другие тематики, включая продвижение сайтов - это завести свой сайт и на нем практиковаться. Кстати, можете посмотреть первый созданный мною сайт по картам для игры Counter-Strike , созданием которых я тогда увлекался. Вот карты и их скрины , созданные стариком Глобатором в те времена, когда он еще не знал, что такое топ-10, тИЦ и PR, и беззаботно резвился на солнышке создавал трехмерные карты 🙂 . Я создал этот сайт за месяц, изучая html и css на практике.
Для того, чтобы выучить html и css, совсем необязательно быть техническим специалистом. К примеру, я вообще гуманитарий и по математике у меня в основном было "2" 🙂 . Так что выучить html и css под силу любому желающему. Перечисленные мною ресурсы подойдут также и для того, чтобы в любой момент вы могли с их помощью выяснить какой-либо интересующий вас момент по html и css.
Сайты для изучения html и css
Начну подборку полезных ресурсов для изучения html и css с сайта, по которому я сам занимался. Это Дикие уроки html , которые написала Валентина Ахметзянова ака Дикарка . Она настолько весело и интересно описала все необходимые моменты, что изучение html и css с помощью ее уроков превращается в увлекательное занятие. Кстати, можете почитать для блога сайт. Диких уроков вполне достаточно, чтобы выучить html и css на необходимом для работы вебмастером уровне.
Представляете, кем бы я был, если бы развивался дальше в теме Фотошопа? Я бы был настоящим монстром! Но я связался с SEO и прозябаю тут, набирая эти буквы скрюченными от мороза пальцами 🙂 . Да шучу, тут тоже тепло и неплохо кормят 🙂 .
Как правило, многие вебмастера загружают свои сайты на хост сразу-же после их создания. При этом они большей частью ориентируются на правильность составления смысла текстового содержания, чем на правильность внутреннего кода страниц.
Валидация сайта
Но есть и другие факторы, которые могут и влияют на позиции сайта. И к ним относятся, в том числе, и технические факторы. Ну а к техническим относятся и валидация сайта. Так что же это такое?
Если простыми словами, то валидация сайта — это проверка кода сайта на техническое соответствие и ошибки. Ну например, вы забыли использовать закрывающий тег — /html. В последнем HTML5, визуально ничего не поменяется. Однако, это ошибка кода.
При написании кода, возможны и другие ошибки. И опять-таки, современный язык гипер разметки «стерпит» многое. Например, «забытие» закрывающего тега /head. И снова вы не увидите разницу. Но она есть))
На самом деле, при написании сайта, ошибок может быть довольно много. И что хуже, некоторые из этих ошибок, могут проявиться и визуально. Ну может блоки поплывут, может выравнивание, а может и еще что-то. Потенциальных ошибок, тысячи. И далеко не все из них, бросаются в глаза.
В чем опасность?
Ну казалось-бы, ну и что тут такого? Да, нужно сказать, что зачастую такие ошибки не видимы. Точнее, невидимы человеком. А ведь страницы нашего сайта могут посетить не только люди, но и поисковые пауки, которые полностью просматривают сайт. И каждую ошибку, которую они находят на сайте, они передают на сервера поисковиков, таких как Яндекс или Гугл.
А поисковики, в свою очередь, видя что на сайте много ошибок кода, вполне могут сделать вывод о том, что сайт плохой. И значит, не будут поднимать его в поиске. Ну а это уже будет означать, что прощай посетители с поиска.
Да, надо признать, определенная пессимизация сайта из-за ошибок валидации, это довольно редкое явление. Но это вполне возможно, а значит, над валидацией обязательно нужно работать. А что для этого нужно сделать? Понятное дело, вначале ошибки нужно найти.
Но поскольку вручную это очень трудоёмкое и ненадежное дело, то для поиска ошибок, используются специальные сервисы, так называемые «Валидаторы».
Валидатор Markup Validation Service.
Этот сервис проверяет правильность кодов HTML и XHTML, которые являются основой большей части страниц при создании практически любого сайта и определяют его внутреннюю структуру. На этот сервис валидатора можно попасть, если пройти по ссылке http://validator.w3.org
Но здесь есть обязательное условие, которое также относится и к другим валидаторам: проверяемый сайт или его проверяемые страницы должны быть закачаны на хостинг. В противном случае, валидатор не будет «знать» адрес сайта и не сможет ничего проверить. Вот сейчас можно уже рассмотреть, как работать на этом валидаторе.
После захода на страницу этого сервиса, отобразиться вся его функциональная картинка. Но большая часть изображённого и написанного к основной проверке не относится и всё своё внимание надо обратить только на окно ввода адреса проверяемой страницы:
Вот именно с него и надо начинать.
Вообще-то, проверка валидации сайта чрезвычайно проста, как и весь наш бренный мир: в адресном окне сервиса надо написать адрес сайта, т.е. его URL и затем нажать «Check». После такого простого действия, валидатор «попыхтит» несколько секунд и выдаст следующее:
Это означает, что никаких ошибок в коде страницы нет и Вы можете быть абсолютно спокойны.
Но также может быть и такой нежелательный вариант:
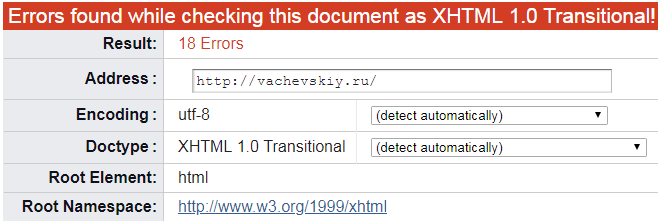
Это уже похуже и означает, что во внутреннем коде проверяемой страницы есть какие-то ошибки. Однако, это совсем не смертельно: просто надо прокрутить страницу ниже и там подробно будут написаны все найденные ошибки в процессе проверки.

Кроме того, валидатор не только перечислит найденные ошибки, но и точно покажет, на какой строке внутреннего кода эти ошибки расположены. Так что долго их искать не придётся. Здесь, ничего не преувеличивая, можно твёрдо сказать, что этот валидор работает прекрасно.
Но это ещё не всё: валидатор не только указывает местоположение обнаруженной ошибки кода, но и даёт достаточно полные рекомендации, каким образом можно устранить эти ошибки. Конечно, для этого не надо лениться и внимательно прочитать всё написанное.
В качестве краткого и обобщенного вывода, можно сказать следующее:
- данный сервис валидатора работает прекрасно и может очень быстро провести проверку сайта.
- Ну и небольшое, но очень приятное дополнение: валидация сайта производиться бесплатно.
- Сейчас можно перейти к следующему этапу: это проверка кода CSS.
Валидатор CSS Validation Service
В общем это вторая функция вышеописанного сервиса, но она «заточена» не для проверки кода HTML и XHTML, а конкретно для проверки правильности кода стиля CSS, расположенного на внешней таблице. А чтобы попасть на страницу сервиса, надо пройти по ссылке http://jigsaw.w3.org/css-validator .
Кстати, здесь стоит отметить нечто приятное: проверка на этом сервисе абсолютно бесплатна. Так что не надо вытаскивать деньги из своего кошелька — пусть они лежат до нужного момента. Однако перейдём к методике работы на этом втором сервисе.
В общем-то вся работа на валидаторе CSS абсолютно идентична проверке на чистоту кода. Поэтому, приводить отдельную картинку адресной строки валидатора нет необходимости. Просто чуть ниже кратко рассмотрим непосредственно порядок самой проверки и всё.
Для этого надо в адресной строке записать URL таблицы CSS, типа «http://мой сайт/style.css» и после этого нажать кнопку с русской надписью «Проверить». Соответственно, этот валидатор тоже несколько секунд «попыхтит» и выдаст искомый результат:
Это значит, что таблица CSS написана правильно и никаких ошибок в ней не обнаружено.
И здесь также есть приятная неожиданность: если прокрутить страницу несколько ниже, то там будет написан оптимизированный код для Вашей таблицы CSS, из которого убраны все лишние надписи и все теги кода будут расставлены в той последовательности, которая соответствует оптимальным рабочим требованиям всех поисковых систем. Остаётся только скопировать этот идеальный образец кода и вставить его в таблицу CSS.
Вполне может быть, что случиться и такой вариант:

Это значит, что обнаружены какие-то ошибки в коде CSS, но пугаться этого совсем не стоит. Сразу внизу под этой красной строкой, валидатор точно укажет, какой тег написан неправильно. Остаётся только в таблице стиля найти эти теги и сделать нужные исправления.

И конечно, после этого закачать исправленную таблицу стиля на хост и при наличии зелёной строки можно с удовольствием скопировать оптимизированный код стиля таблицы CSS. Вполне понятно, что затем лучше всего поменять старый код на новый и оптимизированный.
Краткое резюме.
Выше были рассмотрены две самых основных и обязательных проверки валидации сайта. Без этих проверок даже не стоит открывать индексацию для поисковых систем в robots.txt В противном случае, сайт может быть проигнорирован для индексации поисковыми машинами и будет считаться неисправным с соответствующими санкциями.
Чтобы этого не произошло, надо затратить всего несколько минут, чтобы быть абсолютно спокойным и полностью уверенным в техническом состоянии своего сайта и всех его страниц. Конечно, необходимо ещё произвести дополнительные проверки ссылок и анкоров, видимости сайта на мобильных устройствах и параметры других кодов. Только тогда сайт можно считать готовым для его полного функционирования и для удачного и быстрого продвижению в ТОП.
Заранее хочется сказать, что все остальные проверки проходят также быстро и просто, как и рассмотренные выше — надо только внимательно прочитать порядок работы с валидатором.
Добавлено 19.04.2018г.
Распространенные ошибки валидности при проверке html кода
Решил дополнить статью ошибками HTML кода, которые часто встречаются на сайтах. Во всяком случае у меня их было много)). Сами ошибки валидатор подсвечивает желтым цветом.
1) Error: Character reference was not terminated by a semicolon.

Ошибка: символ не был прерван точкой с запятой — соответственно надо добавить.
2) Warning: Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.

Предупреждение: Раздел не имеет заголовка. Рассмотрите возможность использования элементов h2-h6 для добавления идентифицирующих заголовков ко всем разделам. Тут все понятно, надо добавить хотя бы один подзаголовок. Это даже не ошибка, а рекомендация.
3) Error: Element noindex not allowed as child of element p in this context.
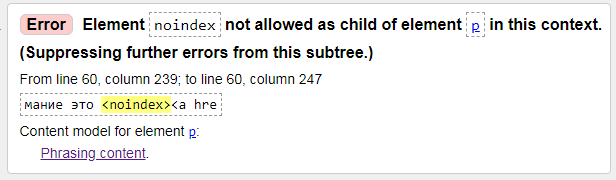
Ошибка: элемент noindex не разрешен как дочерний элемент элемента p в этом контексте. (Подавление дальнейших ошибок из этого поддерева.)
Решение простое, надо закомментировать тег ноиндекс, вид будет таким:
4) Error: The center element is obsolete.
Ошибка: тег «center» устарел — надо заменить, если речь про img то можно использовать атрибут align. Если что-то другое центрировали, то заменить на div.
5) An img element must have an alt attribute, except under certain

Ошибка: Элемент img должен иметь атрибут alt -тут все понятно, надо добавить атрибут альт, даже если он будет незаполненный, то ошибка уйдет.
6) The width attribute on the td element is obsolete. Use CSS instead.
Ошибка: Атрибут «width» на элементе «td» устарел

7) The type attribute is unnecessary for javascript resources

Ошибка: атрибут type не нужен для ресурсов javascript. Решение просто удаляем все лишнее и оставляем только тег «script».
8) The align attribute on the img element is obsolete.

Ошибка: Атрибут align для элемента img устарел. Сделайте выравнивание изображений дивами.